
AWSの機械学習とビッグデータ処理:SageMaker, EMR
AWSのデータ分析系サービスを紹介するシリーズ、第5回の今回は、機械学習のプロセスを効率化する「Amazon SageMaker」と、大規模データの処理を簡単に行える「Amazon EMR」について詳しく解説します。それぞれのサービスの主な機能や各サービスの特徴、さらにそれらを活用したケーススタディを紹介します。これらのサービスが、どのように企業のデータ活用を支援するのか考えていきたいと思います。
目次[非表示]
- 1.Amazon SageMaker
- 1.1.主な機能・特徴
- 1.2.Amazon SageMakerの各サービス
- 1.3.ケーススタディ
- 2.Amazon EMR
- 3.おわりに
シリーズのその他の記事はこちら
Amazon SageMaker
Amazon SageMakerは、フルマネージドサービスであり、機械学習を実施するために必要なトレーニングデータの前処理や作成、機械学習(ML)モデルの構築・学習、さらには学習モデルのデプロイといった一連のプロセスを行う機能を備えています。

主な機能・特徴
-
ワンストップでデプロイまで対応
SageMakerでは、インスタンスの作成からモデルの構築、トレーニング、デプロイまでを一貫して実施することができます。既存の機械学習の仕組みを利用することで、短時間で機械学習を実現することが可能です。
-
Jupyter Notebookをインターフェースとして採用
対話型のデータ分析環境であるJupyter Notebookをインターフェースとして利用しています。この環境では、コードの実行結果をすぐに確認できるため、情報共有が容易になります。
-
主要な機械学習フレームワークに対応
SageMakerは、Apache MXNetやTensorFlowなどの主要な機械学習フレームワークをサポートしています。Dockerコンテナを使用しており、エッジデバイスでも動作可能です。
-
よく使われる機械学習アルゴリズムがインストール済み
PCAやRandom Cut Forestなどのアルゴリズムが事前にインストール・最適化されているため、ワンクリックで機械学習を実行することができます。
-
自動スケーリング
SageMakerは自動的にスケーリングするインフラを提供しており、ベタバイト規模の学習モデルにも対応しています。AWS S3をデータレイクとして利用することで、スムーズな機械学習が可能となります。
このように、Amazon SageMakerは機械学習のプロセスを簡素化し、効率的に実行するための強力なツールです。
Amazon SageMakerの各サービス
Amazon SageMakerには、使用用途に応じたサービスが多くラインナップされています。以下の表にその概要を簡単にご紹介します。
サービス名 |
サービス概要・特徴 |
用途 |
Amazon SageMaker Studio |
データの準備、構築、トレーニング、デプロイまでの全ての機械学習開発ステップを統合的に実行できる環境を提供 |
機械学習プロジェクトの全体管理 |
Amazon SageMaker Data Wrangler |
データの品質を自動で検証し、データの異常を検出するために役立つデータ品質とインサイトレポートを提供するローコードツール |
データ品質管理 |
Amazon SageMaker Ground Trut |
画像やテキストファイル、動画などの未加工データにラベルを追加し、高品質なトレーニングデータセットを作成 |
データラベリング |
Amazon SageMaker Pipelines |
機械学習向けの初めての専用CI/CDサービスを提供し、開発プロセスを効率化 |
CI/CDによる機械学習の自動化 |
Amazon SageMaker Canvas |
コードを必要とせず、機械学習による正確な予測を行う |
ノーコードでの予測分析 |
Amazon SageMaker Autopilot |
機械学習モデルの構築とデプロイのプロセスを自動化し、機械学習ワークフローの各段階を簡素化 |
モデルの自動構築とデプロイ |
Amazon SageMaker JumpStart |
機械学習の活用を促進し、迅速に機械学習を始めるためのソリューションを提供 |
機械学習プロジェクトの迅速な立ち上げ |
Amazon SageMaker Model Monitor |
長期間にわたり機械学習モデルの精度を維持するためのサービス |
モデルのパフォーマンス管理 |
Amazon SageMaker Debugger |
トレーニング中に発生する一般的なエラーを自動で検出し、修正を促すアラート機能を持つサービス |
モデルのトレーニングの監視 |
Amazon SageMaker Clarify |
データの準備やモデルのトレーニング後に、デプロイされたモデルに潜むバイアスを検出するためのサービス |
モデルの公平性評価 |
Amazon SageMaker Edge |
機械学習モデルをエッジデバイスに最適化し、保護、展開を行うことで、エッジデバイスでの機械学習を実現 |
エッジデバイスでのモデル運用 |
Amazon SageMaker Studio Lab |
無料で利用できる機械学習開発環境を提供し、コンピューティングやストレージ、セキュリティを無償で提供。これにより、誰でも機械学習を学び、実践することが可能。 |
機械学習の学習と実験 |
Amazon SageMaker Feature Store |
機械学習モデルの特徴量の保存、共有、管理を行うためのフルマネージドサービス。 |
特徴量管理と共有 |
ケーススタディ
ある金融会社では、投資戦略を強化するために機械学習(ML)モデルを開発しました。このモデルは、株式、債券、コモディティ市場に関するさまざまなデータソースを活用し、すでに本番稼働が承認されています。しかし、データエンジニアは、機械学習による意思決定に使用されるデータが正確、完全、かつ信頼できるものであることを確認する必要があります。また、モデルを本番環境にデプロイするためのデータ準備を自動化することも求められています。
このような要件を満たすために、Amazon SageMakerのワークフローと機械学習リネージトラッキング機能を使用することが最適です。このソリューションを利用することで、データエンジニアはモデルのデータ準備を効率的に行うことができます。
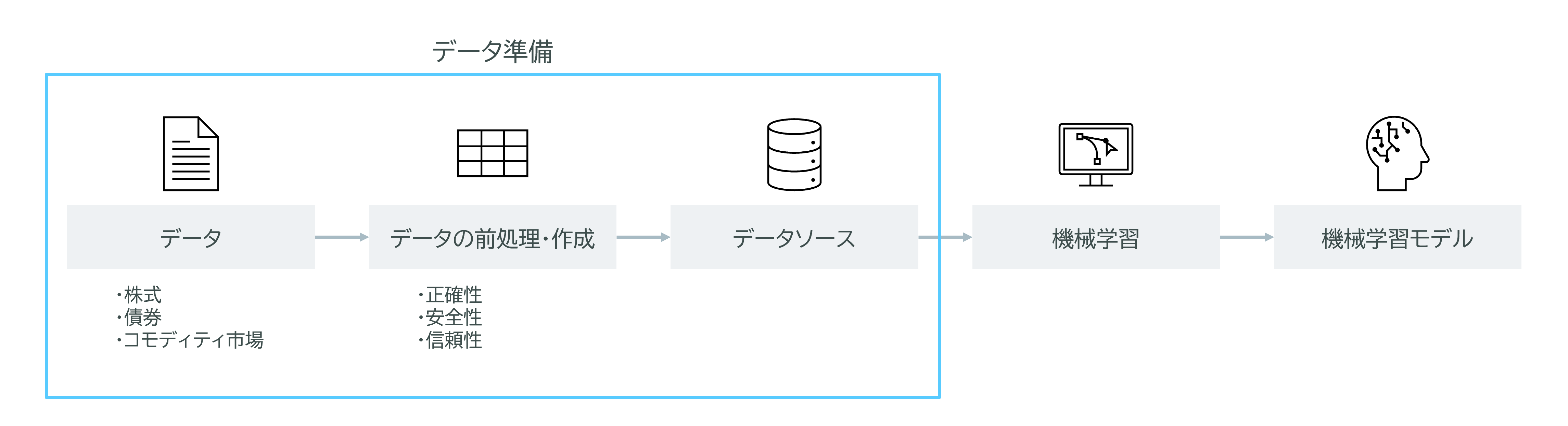
Amazon SageMakerの機械学習リネージトラッキング機能の利点
Amazon SageMakerの機械学習リネージトラッキング機能は、データ準備からモデルのデプロイメントまでの各ステップを追跡・保存することができます。この機能により、ワークフローの再現やモデルのリネージ(系統)の追跡が可能になり、モデルガバナンスや監査基準の確立を支援します。
リネージとは、データやモデルの生成および変換プロセスの履歴を指します。リネージ情報を追跡することで、データやモデルがどのように作成され、どのような変換が行われたかを把握できるため、再現性を高め、監査やコンプライアンスのための透明性を確保することができます。
このように、Amazon SageMakerを活用することで、金融会社は機械学習モデルのデータ準備を自動化し、データの信頼性を確保しつつ、投資戦略を強化するための意思決定を支援することができるのです。
Amazon EMR
Amazon EMRは、大規模なデータの処理、分析、機械学習などを簡単に行うことができるフルマネージドなビッグデータ処理サービスです。

主な機能・特徴
Amazon EMRは、Hadoop、Spark、Hive、Prestoなどのオープンソースフレームワークを使用して、ペタバイトスケールのビッグデータ分析を可能にするAWSのサービスです。
-
スケーラビリティ
EMRでは、データ処理クラスターのサイズを動的にスケールアップおよびスケールダウンでき、必要なリソースをオンデマンドで利用することができます。
-
コスト効率
使用したリソースに対してのみ料金が発生するため、コスト効率が高いです。また、スポットインスタンスを利用することで、さらにコストを削減することが可能です。
-
使いやすさ
AWSマネジメントコンソール、AWS CLI、SDKを使用して、簡単にクラスターを作成・管理することができます。自動化されたプロビジョニング、設定、チューニングにより、運用負荷を軽減することができます。
-
柔軟性
多様なデータソース(Amazon S3、Amazon RDS、DynamoDBなど)と連携し、データの取り込みや出力が容易です。また、ユーザー独自のアプリケーションやライブラリをクラスターにインストールしてカスタマイズすることも可能です。
-
セキュリティ
データの暗号化(転送中および保存時)、IAMによるアクセス制御、VPCによるネットワーク分離などのセキュリティ機能を提供しています。
利用シーン
-
データトランスフォーメーションとETL
Amazon EMRは、大量のデータを抽出、変換、ロードするプロセスを支援し、データウェアハウスやデータレイクにデータを統合します。例えば、ログデータを収集し、フィルタリングと集計を行った後、データウェアハウスにロードすることができます。
-
ビッグデータ分析
大規模なデータセットに対して複雑なクエリや分析を実行することができ、顧客行動データを分析してマーケティング戦略を最適化するのに役立ちます。
-
リアルタイムデータ処理
EMRは、ストリーミングデータのリアルタイム分析にも対応しています。例えば、センサーデータをリアルタイムで監視し、異常検知を実施することが可能です。
-
機械学習
大規模なデータセットを用いた機械学習モデルのトレーニングと評価にも対応しており、顧客の購買履歴を基にレコメンデーションエンジンを構築することができます。
このように、Amazon EMRは多様なビッグデータ処理のニーズに応える強力なツールであり、企業がデータから価値を引き出す手助けをします。
ケーススタディ
ある企業は、オンプレミスのApache HadoopクラスターをAmazon EMRに移行する計画を立てています。この移行にあたり、データカタログを永続ストレージソリューションに移行する必要があります。現在、同社はHadoopクラスター上のオンプレミスのApache Hiveメタストアにデータカタログを保存していますが、移行にはサーバレスソリューションを求めています。
このような要件を満たすために、最もコスト効率の良いソリューションとして、次の手順が提案されました。まず、Amazon EMRでHiveメタストアを設定し、既存のオンプレミスのHiveメタストアをAmazon EMRに移行します。その後、Amazon Glue Data Catalogを使用して、会社のデータカタログを外部データカタログとして保存します。
Apache HadoopクラスターとHiveメタストアの理解 Apache Hadoopクラスターは、ビッグデータの分散処理とストレージを実現するためのフレームワークで構築されたコンピュータ群です。一方、HiveメタストアはApache Hiveの重要なコンポーネントであり、Hiveテーブルやデータベースのメタデータ(データのスキーマ情報)を管理するためのデータカタログです。
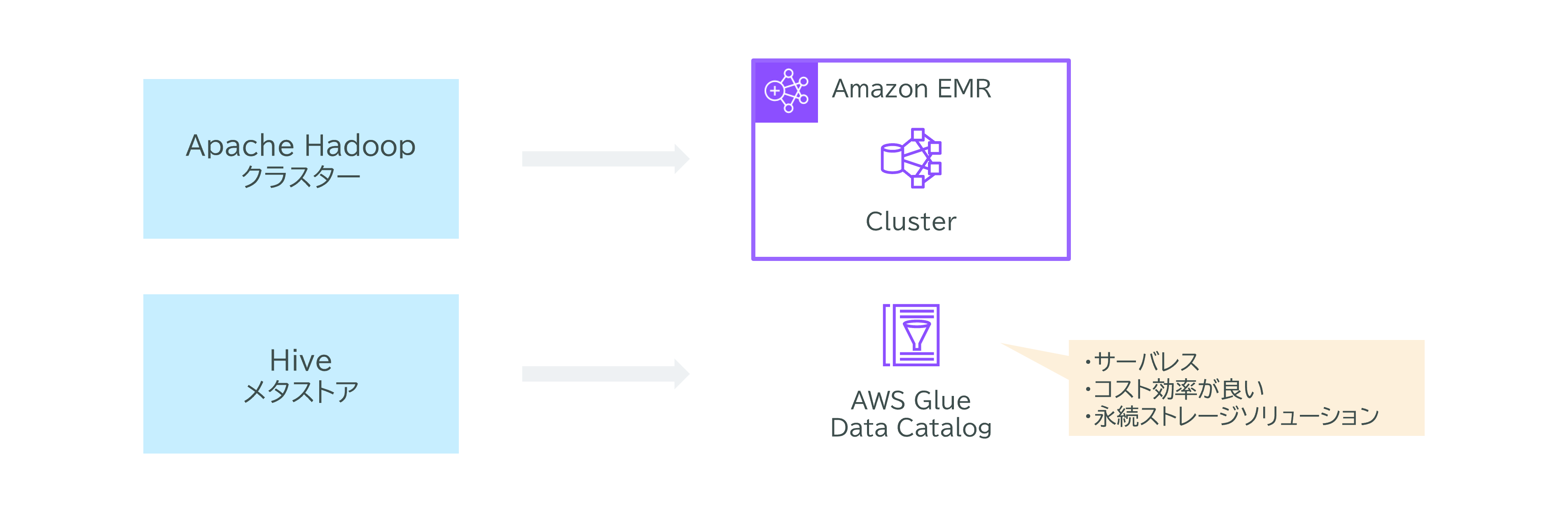
Amazon Glue Data Catalogを活用したサーバーレスソリューションの活用
-
サーバレス管理
Amazon Glue Data Catalogはサーバレスソリューションであり、管理を必要としないため、運用負荷を軽減できます。
-
コスト効率
利用した分だけ課金されるため、コスト効率が高く、無駄な支出を抑えることができます。
-
安全なメタデータ保存
Glue Data Catalogはデータカタログの永続ストレージとして機能し、データのメタデータを安全に保存することができます。
このように、企業はAmazon EMRとAmazon Glue Data Catalogを活用することで、オンプレミスのApache Hadoopクラスターからの移行をスムーズに行い、データカタログの管理を効率化し、コストを抑えることができるのです。
おわりに
ここまで、AWSの機械学習サービスであるAmazon SageMakerとビッグデータ処理サービスであるAmazon EMRの特徴と活用方法について詳しくご紹介しました。Amazon SageMakerは、機械学習プロセスを簡素化し、効率的に実行するための強力なツールであり、データの前処理からモデルのデプロイまでを一貫してサポートします。一方、Amazon EMRは、大規模なデータの処理や分析をフルマネージドで行うことができ、スケーラビリティやコスト効率に優れたビッグデータ処理のソリューションです。これらのサービスを活用することで、企業は迅速かつ正確な意思決定を行うことができ、データから価値を引き出すことが可能になります。次回は、ワークフロー処理に関連するサービスをまとめたいと思います。引き続き、お楽しみにしてください!
Kyriosでは、データ分析プラットフォームの構築・運用を支援しています。詳細は、下記のページをご覧ください。








