
AWSデータ分析基盤における関連サービス解説:Redshift、DynamoDB、Athena
この記事は、AWSのデータ分析系サービスを紹介するシリーズの第2回として、今回は、データの統合や管理からクエリ、分析に関連する基盤構築に関するサービスとして、Amazon Redshift、Amazon DynamoDB、Amazon Athenaについてご紹介します。それぞれのサービスについて概要を解説した後、AWS DEAの問題をベースにしたケーススタディを使用して、実践的にご紹介します。
目次[非表示]
その他のデータ分析関連の記事はこちら
Amazon Redshift
AWS Redshiftは、高速でフルマネージド型のデータウェアハウスサービスです。このサービスは、大規模なデータ分析を迅速に行うために設計されています。

主な機能・特徴
-
高速性
Redshiftは、大規模データセットを高速に分析することに特化しています。列指向データベースであるため、集計や分析処理を迅速に行うことができます。
-
フルマネージド
インフラストラクチャの管理が不要で、運用管理の負担が軽減されます。これにより、ユーザーはデータ分析に集中することができます。
-
コスト効率
クエリの最適化により、ストレージ使用量とコストを削減できます。これにより、効率的にリソースを利用することができます。
-
迅速な分析
エクサバイト規模のデータレイクに保管されたデータや、配信ストリームに対するほぼリアルタイムの分析を単一のサービスで実現できます。これにより、迅速な意思決定が可能になります。
-
機械学習連携
SQLを使用して機械学習モデルの構築、トレーニング、デプロイが可能です。これにより、高度な分析をサポートします。
利用シーン
-
データ分析
Redshiftは、顧客行動分析、市場動向分析、財務パフォーマンス分析など、大規模なデータセットを用いた分析業務に利用されます。ほぼリアルタイム分析により、迅速な意思決定が可能です。
-
データレイク
データレイクに蓄積された多様なデータを統合し、分析基盤として活用することができます。企業全体のデータ分析基盤やデータ統合プラットフォームの構築が可能です。
-
データストリーミング分析
ほぼリアルタイムなデータストリーミング分析を行うことができます。顧客行動分析、金融市場分析、IoTデータ分析など、さまざまな用途に対応しています。
-
ログデータ分析
大量のログデータを高速に処理・分析し、不正アクセスや攻撃の検知に活用することができます。
このように、AWS Redshiftは大規模データの迅速な分析を可能にし、さまざまなビジネスニーズに応える強力なデータウェアハウスサービスです。
ケーススタディ
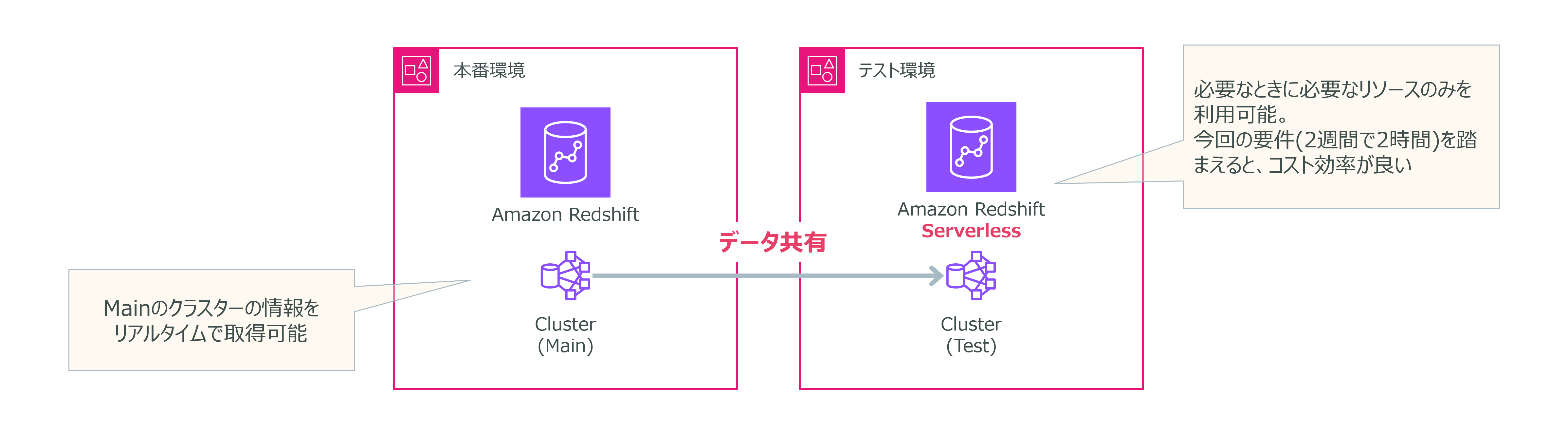
ある企業では、Amazon Redshiftクラスターを運用しており、データエンジニアは別のテスト環境で分析を行うためのソリューションを設計する必要があります。このテスト環境では、メインのRedshiftクラスターからデータを使用し、2週間ごとに2時間のみ利用される予定です。企業は、これらの要件を満たすために、最もコスト効率の良い方法を模索しています。
Amazon Redshift Serverlessを利用したテストクラスター構築
企業は、メインのRedshiftクラスターからテストクラスターへのデータ共有を作成し、テスト環境にはAmazon Redshift Serverlessを利用することを決定しました。このアプローチにより、以下の利点が得られます。
-
データ共有の効率性
Redshiftのデータ共有機能を利用することで、メインクラスターのデータをリアルタイムでテストクラスターで利用できます。これにより、データの移動が不要となり、迅速な分析が可能になります。
-
コスト効率の向上
Amazon Redshift Serverlessを使用することで、必要なときにのみリソースを使用できます。テスト環境は、2週間ごとに2時間のみの使用であるため、リソースを必要な時だけ利用することでコストを抑えることができます。
-
本番環境との連携
本番環境であるメインクラスターの情報をリアルタイムで取得できるため、テスト環境での分析が実際のデータに基づいて行われ、より信頼性の高い結果を得ることができます。
このように、Amazon Redshiftを活用したデータ共有とServerlessの機能により、企業は効率的かつコスト効果の高いテスト環境を実現することができます。
Amazon DynamoDB
Amazon DynamoDBは、フルマネージドなNoSQLデータベースサービスです。このサービスは、単桁ミリ秒の低レイテンシで、高いスケーラビリティとパフォーマンスを持つデータストレージを提供します。

主な機能・特徴
-
スケーラビリティ
DynamoDBは自動的にスケールアップおよびスケールダウンが可能です。アプリケーションのトラフィックに応じて、必要なリソースを自動的に調整しますので、急なトラフィックの増加にも柔軟に対応できます。
-
高可用性と耐障害性
データは自動的に複数AZへレプリケートされ、システム障害に対する耐性が高まります。これにより、常に高い可用性を維持することができます。
-
低レイテンシー
ミリ秒単位の応答時間を実現するため、高速なデータアクセスが可能です。これにより、ユーザーはストレスなくデータを取得できます。
-
フルマネージド
サーバーのセットアップ、パッチ適用、バックアップ、レプリケーションなどの管理作業はAWSが行いますので、ユーザーはインフラ管理に時間を費やす必要がありません。
利用シーン
-
Webアプリケーションのバックエンド
自動的にスケールアップおよびスケールダウンが可能なため、トラフィックの増減に柔軟に対応できます。たとえば、ソーシャルメディアアプリのユーザープロファイル情報を保存し、ユーザーがログインするたびに迅速にデータを取得することができます。
-
IoTデバイスデータの収集
高スループットと低レイテンシを提供し、センサーデータやデバイスからのログデータを効率的に保存・検索できます。たとえば、スマートホームデバイスからの温度や湿度のデータを収集し、リアルタイムでモニタリングおよび解析することが可能です。
-
フルマネージドサービスとしての活用
開発者はインフラ管理に時間を費やす必要がなく、アプリの開発に集中できます。
-
リアルタイムデータ分析
DynamoDBはリアルタイムでデータを収集し、即座にクエリを実行できるため、オンライン広告キャンペーンのクリックデータを収集し、リアルタイムで効果を測定してキャンペーンの調整を行うことも可能です。
このように、Amazon DynamoDBは多様なニーズに応じた機能を提供し、さまざまなアプリケーションでの利用が期待されます。
ケーススタディ
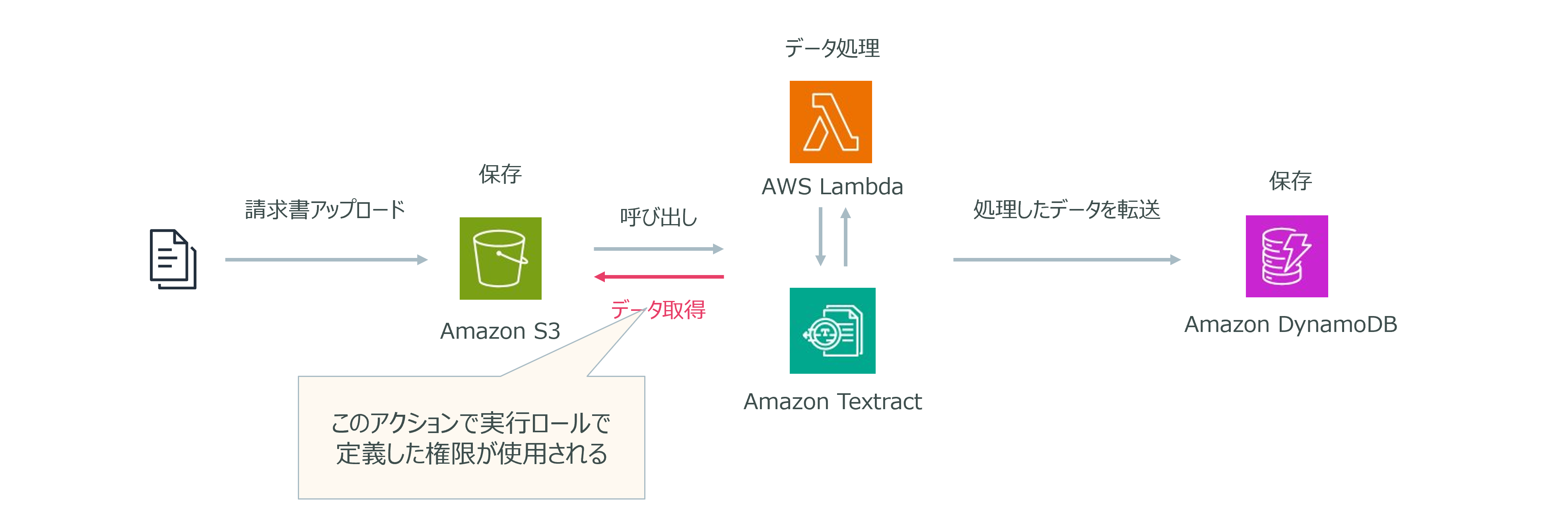
ある金融企業では、支払い済みの請求書をAmazon S3バケットに保存しています。請求書がアップロードされると、AWS Lambda関数がAmazon Textractを使用してPDFデータを処理し、その結果をAmazon DynamoDBに保存する仕組みを採用しています。
現在、このLambda実行ロールには広範なS3アクセス許可が付与されており、セキュリティのベストプラクティスに従って、アクセス許可を見直す必要があります。具体的には、Lambda関数が必要とする最小限の権限のみを付与することで、セキュリティリスクを低減したいと考えています。
【図】
Lambdaと使用する場合のDynamoDBのアクセス許可
この要件を満たすために、企業は以下の2つの変更を行います:
- アクションの変更: Lambda実行ロールのアクションを「s3:*」から「s3:GetObject」に変更します。これにより、Lambda関数はオブジェクトを取得する権限のみを持つことになります。
- リソースの限定: リソースの指定を「*」から特定のバケットARNに限定します。これにより、Lambda関数は指定されたS3バケット内のオブジェクトにのみアクセスできるようになります。
これらの変更を実施することで、Lambdaの実行ロールには最小限の権限が付与され、セキュリティのベストプラクティスに沿った形でのアクセス管理が実現されます。このアプローチにより、企業はデータの安全性を高めつつ、業務プロセスを効率的に運営することが可能になります。
Amazon Athena
Amazon Athenaは、AWSが提供するデータ分析サービスです。このサービスでは、Amazon S3に格納されているデータを直接分析することが可能です。サーバーレスであるため、セットアップが不要で、使用した分だけコストが発生する従量課金制を採用しています。

主な機能・特徴
-
サーバーレス
インフラストラクチャの管理が不要で、ユーザーはクエリの実行のみを行えばよいのが特徴です。これにより、煩わしい設定や管理から解放され、データ分析に集中できます。
-
SQLサポート
SQLを使用してデータにクエリを実行できるため、データ分析が容易です。既存のSQLスキルを活かして、直感的にデータを扱うことができます。
-
データソース
主にAmazon S3に保存されたデータを対象としており、CSV、JSON、Parquet、ORCなどのフォーマットに対応しています。これにより、多様なデータ形式を扱うことができます。
-
料金体系
クエリ実行時にスキャンされたデータ量に基づいて課金されるため、コスト効率が高いです。必要な分だけ支払うことで、無駄なコストを抑えることができます。
利用シーン
-
データ分析
大量のログデータやイベントデータを分析するために使用されます。たとえば、ウェブサイトのトラフィック分析やアプリケーションの使用状況の把握などに役立ちます。
-
ビジネスインテリジェンス
BIツール(例: Amazon QuickSight)と統合することで、データの可視化やダッシュボード作成が可能です。これにより、データからインサイトを得やすくなります。
-
データレイクのクエリ
データレイクに保存されたデータに対して直接クエリを実行し、必要な情報を迅速に取得することができます。これにより、データの利活用が促進されます。
-
ETLプロセスの一部
データの抽出、変換、ロード(ETL)プロセスの一環として、データをクエリして変換し、他のシステムにロードするために利用されます。
-
アドホッククエリ
データに対する即時の質問や分析を行うために、迅速にクエリを実行することが可能です。これにより、必要な情報を迅速に得ることができます。
このように、Amazon Athenaはデータ分析を効率化するための強力なツールであり、さまざまなユースケースに対応しています。
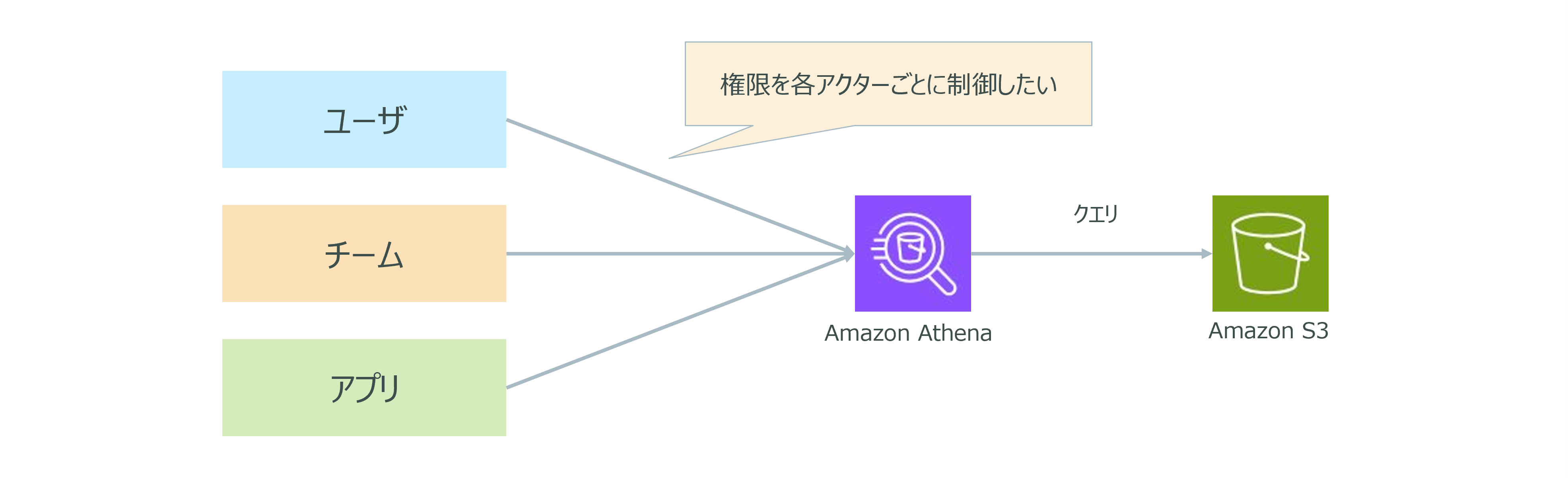
ケーススタディ
ある企業では、Amazon S3に保存されているデータに対して、Amazon Athenaを利用して1回限りのクエリを実行しています。この企業は、複数のユーザー、チーム、アプリケーションが同じAWSアカウント内で作業しているため、クエリプロセスやクエリ履歴へのアクセスを適切に分離する権限制御が必要です。
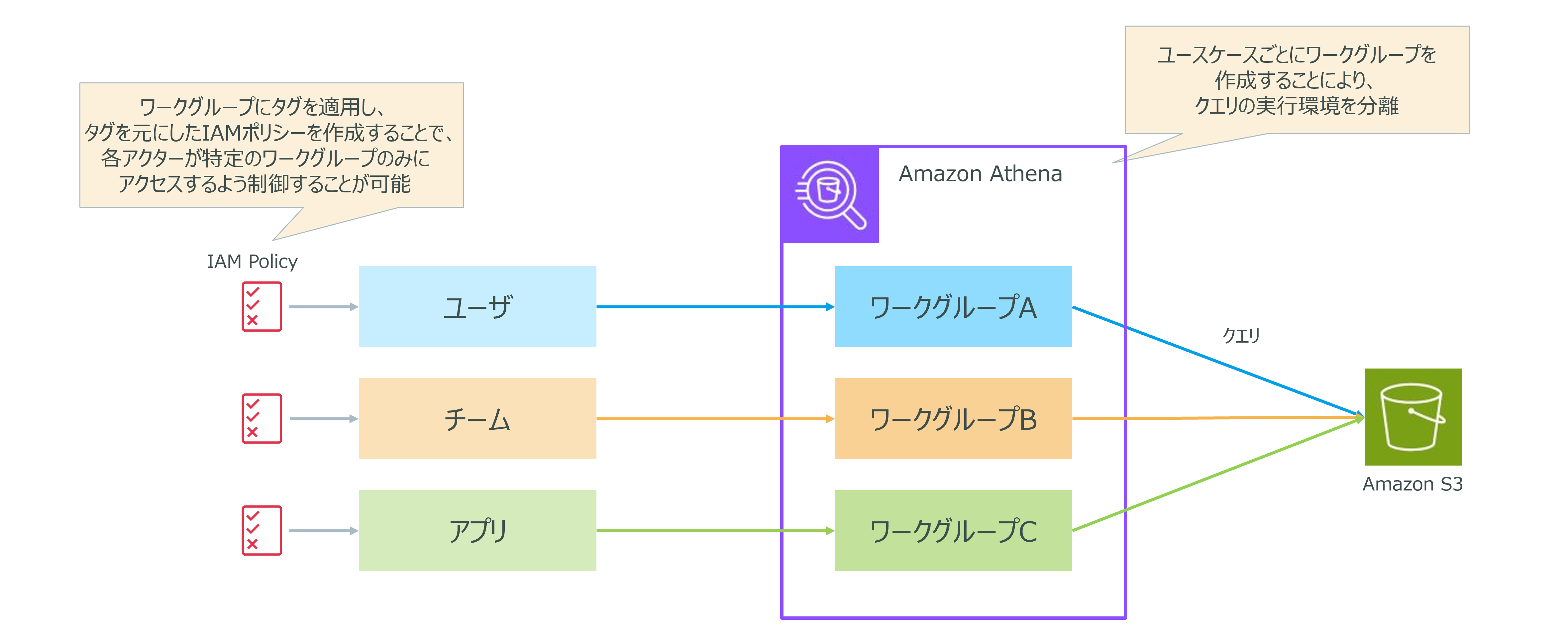
この要件を満たすために、企業はユースケースごとにAthenaのワークグループを作成することを決定しました。各ワークグループには特定のタグを適用し、これらのタグを基にしたIAMポリシーを作成することで、ユーザーやアプリケーションが特定のワークグループにのみアクセスできるようにします。
Athenaワークグループの利点
-
クエリの分離
ユースケースごとにワークグループを作成することで、異なるクエリの実行環境を分離し、各ユーザーが自分のクエリやクエリ履歴を見つけやすくなります。これにより、他のユーザーのクエリに影響を与えることなく、自分の作業に集中できます。
-
アクセス制御
タグを使用することで、各ワークグループに対する適切な権限を設定するIAMポリシーを作成できます。この仕組みにより、特定のユーザーやチームが必要なデータにのみアクセスできるようになり、セキュリティが向上します。
-
管理の容易さ
ワークグループ全体の設定を行うことで、すべてのクエリに対して共通の使用ルールを適用できます。また、ワークグループを無効にすることで、その間はクエリの実行ができなくなるため、必要に応じてクエリの利用を制御することが可能です。
このように、Amazon Athenaのワークグループを活用することで、企業はデータクエリの効率性とセキュリティを高めることができます。
おわりに
ここまで、AWSのデータ分析系サービスであるAmazon Redshift、Amazon DynamoDB、Amazon Athenaの特徴と活用方法について詳しくご紹介しました。これらのサービスは、それぞれ異なるニーズに応じてデータの統合、管理、分析を効率化し、データエンジニアが抱える課題を解決する強力なツールです。今後、データ分析の重要性はますます高まると予想されますので、これらのサービスを活用することで、企業は迅速かつ正確な意思決定を行うことができるでしょう。次回も引き続き、データ分析に役立つAWSのサービスを取り上げていきますので、ぜひご期待ください。
Kyriosでは、AWS Glueをはじめ、データ分析プラットフォームの構築・運用を支援しています。詳細は、下記のページをご覧ください。








