
フルマネージドETLツール「AWS Glue」によるデータ統合と機械学習の導入
AWSのフルマネージドのデータ統合サービス「AWS Glue」をご存じでしょうか。このサービスは、データの抽出、変換、ロード(ETL)を効率的に自動化し、データ処理を簡素化します。本記事では、各機能の詳細やワークフローに加え、AWS Glue DataBrewについても紹介します。また、ユースケースを2つ取り上げ、AWS Glueをどのように活用できるかのイメージを掴んでいただければと思います。AWS Data Engineer Associate (DEA)資格の勉強にも活用いただければと思います!
目次[非表示]
- 1.AWS Glueとは
- 2.AWS Glueの各機能
- 2.1.AWS Glue Data Catalog
- 2.2.クローラー
- 2.3.ETL ジョブ
- 2.4.トリガー
- 3.AWS Glueの一般的なワークフロー
- 4.AWS Glue DataBrew
- 4.0.1.主な機能
- 5.ユースケース① AWS Glueを活用したデータパイプラインの最適化
- 6.ユースケース② 保険データのセキュリティと機械学習モデル化
- 7.おわりに
AWS Glueとは
AWS Glueは、Amazonが提供するフルマネージドのデータ統合サービスで、データの抽出、変換、ロード(ETL)を効率的に自動化します。サーバーレス環境で動作するため、インフラストラクチャの管理が不要で、必要なリソースをオンデマンドで利用できるためコスト効率が高いのが特徴です。AWS Glueの中心的な機能である「AWS Glue Data Catalog」は、データのメタデータを管理する中央リポジトリとして機能し、データの検索や整理を容易にします。また、さまざまなデータフォーマットやデータソースに対応しており、統合や変換がシームレスに行えます。

ETLジョブの作成には、GUIベースのツールやSparkエンジンを利用したコードの記述が可能で、ジョブのスケジューリングも柔軟に設定できます。さらに、Amazon S3やRedshift、AthenaなどのAWSサービスと統合できるため、データ分析や機械学習の前処理、データウェアハウスの構築、データ移行といった幅広い用途で活用されています。このようにAWS Glueは、スケーラブルかつ自動化されたデータ処理を実現し、データ統合の複雑さを大幅に軽減するサービスです。
データ分析の基礎については、次の記事が参考になります。
AWS Glueの各機能
AWS Glue Data Catalog
AWS Glue Data Catalogは、ETLワークフローのためのメタデータストアです。このストアには、テーブル定義やジョブ定義、その他の制御情報が含まれています。データソースやターゲットの情報を一元管理し、ETLジョブで使用されるメタデータを保存します。
ETLとは
ETLは「Extract, Transform, Load」の略で、データの抽出、変換、ロードのプロセスを指します。
メタデータとは
メタデータはデータについての情報であり、「データを説明するデータ」とも言われます。具体的には、以下のような内容が含まれます:
- ファイル名
- 作成日
- 作成者
- ファイル形式
- ファイルサイズ
クローラー
クローラーは、データソースに接続してデータスキーマを推測し、データカタログにメタデータテーブルを作成するプログラムです。データソースをスキャンしてテーブル定義を自動的に生成し、データカタログを更新します。
データスキーマとは?
データスキーマは、データがどのような形式で格納されるかを示す情報の集合です。
<データスキーマの例>
顧客情報を管理するテーブルの例を挙げます。
- テーブル名: 顧客
- 列情報:
1. 顧客ID (整数型, 主キー)
2. 名前 (文字列型, 非NULL)
3. メールアドレス (文字列型, 一意制約)
4. 登録日 (日付型)
ETL ジョブ
ETLジョブは、データを抽出(Extract)、変換(Transform)、ロード(Load)するためのビジネスロジックをサーバーレスで実行します。Apache Sparkスクリプトを使用してデータを処理し、指定されたターゲットにロードします。
トリガー
Triggersは、スケジュールやイベントに基づいてジョブを実行するメカニズムです。定期的なスケジュールや特定のイベントに応じてETLジョブを自動的に開始します。
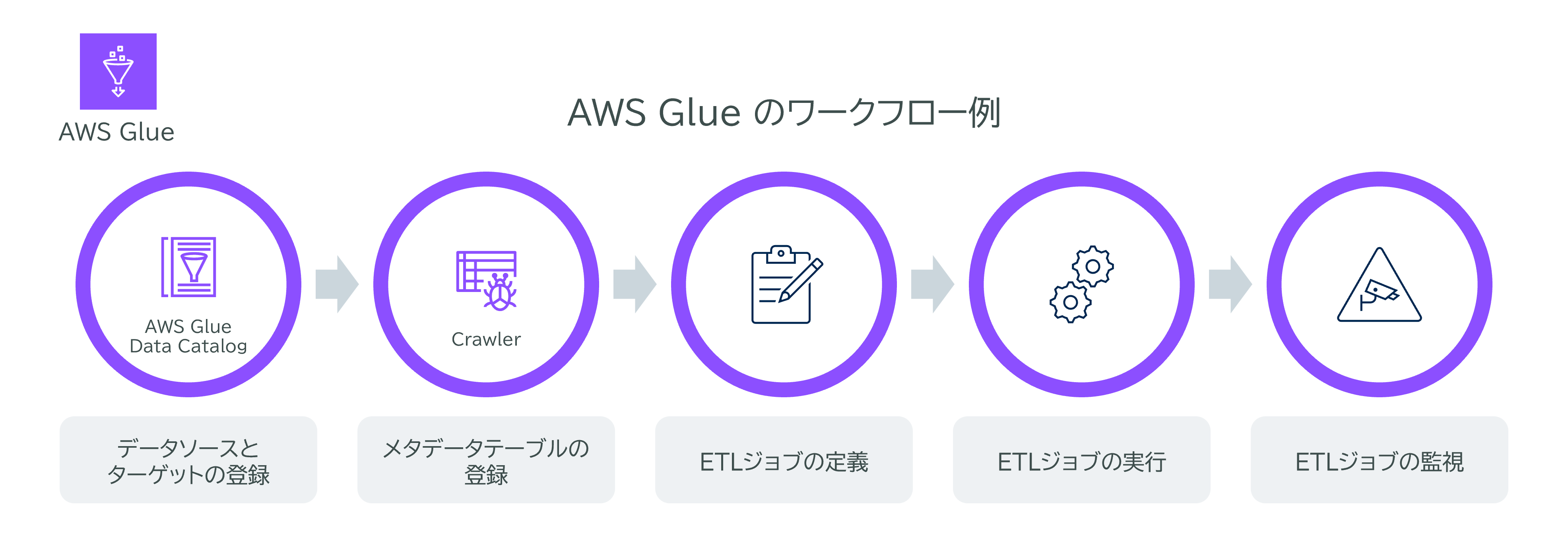
AWS Glueの一般的なワークフロー
AWS Glueを利用する一般的なワークフローは以下の通りです。
-
データソースとターゲットの定義
AWS Data Catalogにデータソースとターゲットを登録します。
-
クローラーの使用
Crawlerを実行して、データソースからテーブルメタデータをデータカタログに登録します。
-
ETLジョブの定義
変換スクリプトを使用してデータを移動および処理するETLジョブを定義します。
-
ジョブの実行
ジョブをオンデマンドで実行するか、トリガーに基づいて自動的に実行します。
-
ジョブの監視
ダッシュボードを使用してジョブのパフォーマンスを監視します。
AWS Glue DataBrew
AWS Glue DataBrewは、コードを書くことなくデータを視覚的に準備および変換できるデータ準備ツールです。

主な機能
-
データのクリーニングと標準化
データの欠損値の補完、重複の削除、データ型の変換など、データクリーニングのための豊富な機能を提供します。
-
データの変換
データのフィルタリング、並べ替え、集約、結合、分割など、さまざまなデータ変換操作が可能です。
-
視覚的なデータ探索
データの分布、統計情報、異常値などを視覚的に確認できるインタラクティブなダッシュボードを提供します。 -
ステップバイステップのガイド
データ準備の各ステップをガイドし、ユーザーが簡単にデータを準備できるようにサポートします。
-
レシピの作成
データ変換のステップをレシピとして保存し、再利用可能なテンプレートとして他のデータセットに適用できます。
-
スケジュールされたジョブ
レシピをスケジュールされたジョブとして設定し、定期的にデータ変換を自動実行することが可能です。
ユースケース① AWS Glueを活用したデータパイプラインの最適化
ある企業がAWS Glueを使用して、レコードを処理するデータパイプラインをデプロイしました。このデータパイプラインでは、JSON形式のイベントデータが含まれており、さらにbase64でエンコードされた画像を含む可能性もあります。このように複雑なデータ構造を扱うプロジェクトにおいて、AWS Glueはその強力なETL機能を通じて、効率的なデータ処理を実現します。
しかし、データエンジニアは、初期設定で10個のデータ処理ユニット(DPU) を使用しているにもかかわらず、ジョブの実行時には数百のDPUまでスケールされることがあり、これにより処理が遅延するケースが発生しています。このような状況では、適切なDPU容量を確保することが重要になります。DPUの最適化がさらなるパフォーマンスの向上に寄与するからです。
AWS Glueの「ジョブ実行モニタリング」セクション
この場合、データエンジニアはデータパイプラインをモニタリングし、どの程度のDPUが適切かを判断する必要があります。そのために有効なアプローチの一つは、AWS Glueコンソールの「ジョブ実行モニタリング」セクションを利用することです。このセクションでは、過去のジョブ実行結果に基づく詳細なメトリクスとパフォーマンスデータが提供されます。
<ジョブ実行モニタリング>セクションで得られる情報
- ジョブの実行時間
- 各DPUのリソース使用量
- スケール時のパフォーマンス
これにより、実際のデータ処理に必要なDPU数を可視化し、データパイプラインの性能を最大化するための判断材料を得ることができます。これらのメトリクスを活用することで、データエンジニアはより効率的かつ迅速に処理を行えるようになり、企業全体のデータ処理能力を高めることが期待されます。
ユースケース② 保険データのセキュリティと機械学習モデル化
ある保険会社では、自動車保険に関連するデータを用いて、リスク分析のための機械学習(ML) モデルをAmazon SageMakerで構築しています。このデータには個人を特定できる情報(PII)が含まれていますが、これらの情報をそのまま使用することは、プライバシーやセキュリティの観点からリスクが高いため、機械学習モデルではPIIを使用すべきではありません。
また、規制により、保険データはAWS Key Management Service (AWS KMS)キーで暗号化することが義務付けられています。このような状況において、データエンジニアは機械学習モデルで利用する保険データを適切に提供する手段を選ぶ必要があります。
AWS Glue DataBrewで暗号化したデータを処理
この要件を満たすための最もコスト効率の良い方法は、次の2つの方法です。
-
AWS KMSによる暗号化
まず、AWS KMS (サーバー側の暗号化、SSE-KMS) を使用して暗号化されたAmazon S3バケットにデータを送信します。この方法は、保険データを安全に保存するための最適なソリューションです。SSE-KMSにより、データが暗号化された状態でS3に保存されるため、外部からのアクセスに対するリスクを軽減できます。このプロセスは、機械学習モデルにデータを提供する上で、最も費用対効果が高い選択肢となります。
-
AWS Glue DataBrewによるデータ準備
次に、AWS Glue DataBrewを使用してデータの取り込みを設定し、PII情報をマスクします。DataBrewは、ビジュアルデータ準備ツールであり、プログラムを書くことなく簡単にデータのクリーンアップや正規化を行うことができます。特に、DataBrewはデータ準備プロセス中にPIIデータを難読化するためのデータマスキングメカニズムを提供しており、規制を遵守しながら安全にデータを処理することができます。
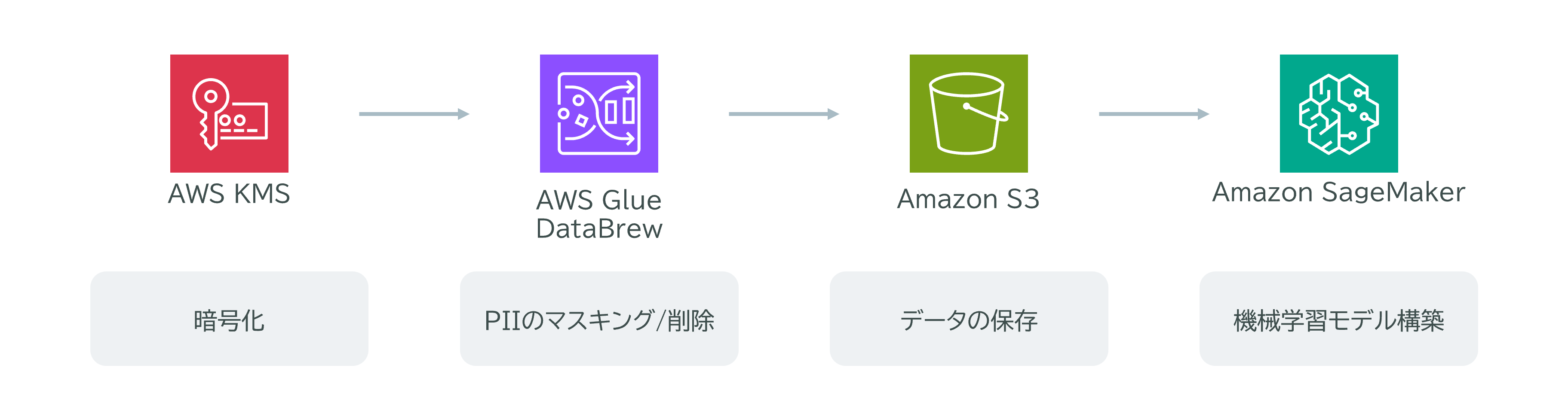
このように、AWS KMSを活用した暗号化と、DataBrewを用いたデータマスキングを組み合わせることにより、保険会社は規制に準拠しつつ、データのプライバシーを保護し、コスト効率よく機械学習のためのデータを提供することができるのです。データエンジニアはこれらのサービスを活用することで、安全かつ効率的なデータ処理パイプラインを構築することができます。
おわりに
以上、本記事ではAWS Glueの機能について、一般的なワークフローやユースケースをまじえてご紹介しました。AWS Glueを利用することで、データ分析に必要な処理の複雑さを軽減し、データ活用を行うことができます。ぜひ活用してみてください!
関連サービス
Kyriosでは、AWS Glueをはじめ、データ分析プラットフォームの構築・運用を支援しています。詳細は、下記のページをご覧ください。








